#Elasticsearch Framework
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
$AIGRAM - your AI assistant for Telegram data
Introduction
$AIGRAM is an AI-powered platform designed to help users discover and organize Telegram channels and groups more effectively. By leveraging advanced technologies such as natural language processing, semantic search, and machine learning, AIGRAM enhances the way users explore content on Telegram.
With deep learning algorithms, AIGRAM processes large amounts of data to deliver precise and relevant search results, making it easier to find the right communities. The platform seamlessly integrates with Telegram, supporting better connections and collaboration. Built with scalability in mind, AIGRAM is cloud-based and API-driven, offering a reliable and efficient tool to optimize your Telegram experience.
Tech Stack
AIGRAM uses a combination of advanced AI, scalable infrastructure, and modern tools to deliver its Telegram search and filtering features.
AI & Machine Learning:
NLP: Transformer models like BERT, GPT for understanding queries and content. Machine Learning: Algorithms for user behavior and query optimization. Embeddings: Contextual vectorization (word2vec, FAISS) for semantic search. Recommendation System: AI-driven suggestions for channels and groups.
Backend:
Languages: Python (AI models), Node.js (API). Databases: PostgreSQL, Elasticsearch (search), Redis (caching). API Frameworks: FastAPI, Express.js.
Frontend:
Frameworks: React.js, Material-UI, Redux for state management.
This tech stack powers AIGRAM’s high-performance, secure, and scalable platform.
Mission
AIGRAM’s mission is to simplify the trading experience for memecoin traders on the Solana blockchain. Using advanced AI technologies, AIGRAM helps traders easily discover, filter, and engage with the most relevant Telegram groups and channels.
With the speed of Solana and powerful search features, AIGRAM ensures traders stay ahead in the fast-paced memecoin market. Our platform saves time, provides clarity, and turns complex information into valuable insights.
We aim to be the go-to tool for Solana traders, helping them make better decisions and maximize their success.
Our socials:
Website - https://aigram.software/ Gitbook - https://aigram-1.gitbook.io/ X - https://x.com/aigram_software Dex - https://dexscreener.com/solana/baydg5htursvpw2y2n1pfrivoq9rwzjjptw9w61nm25u
2 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
Built-in Logging with Serilog: How EasyLaunchpad Keeps Debugging Clean and Insightful

Debugging shouldn’t be a scavenger hunt.
When things break in production or behave unexpectedly in development, you don’t have time to dig through vague error messages or guess what went wrong. That’s why logging is one of the most critical — but often neglected — parts of building robust applications.
With EasyLaunchpad, logging is not an afterthought.
We’ve integrated Serilog, a powerful and structured logging framework for .NET, directly into the boilerplate so developers can monitor, debug, and optimize their apps from day one.
In this post, we’ll explain how Serilog is implemented inside EasyLaunchpad, why it’s a developer favorite, and how it helps you launch smarter and maintain easier.
🧠 Why Logging Matters (Especially in Startups)
Whether you’re launching a SaaS MVP or maintaining a production application, logs are your eyes and ears:
Track user behavior
Monitor background job status
Catch and analyze errors
Identify bottlenecks or API failures
Verify security rules and access patterns
With traditional boilerplates, you often need to configure and wire this up yourself. But EasyLaunchpad comes preloaded with structured, scalable logging using Serilog, so you’re ready to go from the first line of code.
🔧 What Is Serilog?
Serilog is one of the most popular logging libraries for .NET Core. Unlike basic logging tools that write unstructured plain-text logs, Serilog generates structured logs — which are easier to search, filter, and analyze in any environment.
It supports:
JSON log output
File, Console, or external sinks (like Seq, Elasticsearch, Datadog)
Custom formats and enrichers
Log levels: Information, Warning, Error, Fatal, and more
Serilog is lightweight, flexible, and production-proven — ideal for modern web apps like those built with EasyLaunchpad.
🚀 How Serilog Is Integrated in EasyLaunchpad

When you start your EasyLaunchpad-based project, Serilog is already:
Installed via NuGet
Configured via appsettings.json
Injected into the middleware pipeline
Wired into all key services (auth, jobs, payments, etc.)
🔁 Configuration Example (appsettings.json):
“Serilog”: {
“MinimumLevel”: {
“Default”: “Information”,
“Override”: {
“Microsoft”: “Warning”,
“System”: “Warning”
}
},
“WriteTo”: [
{ “Name”: “Console” },
{
“Name”: “File”,
“Args”: {
“path”: “Logs/log-.txt”,
“rollingInterval”: “Day”
}
}
}
}
This setup gives you daily rotating log files, plus real-time console logs for development mode.
🛠 How It Helps Developers
✅ 1. Real-Time Debugging
During development, logs are streamed to the console. You’ll see:
Request details
Controller actions triggered
Background job execution
Custom messages from your services
This means you can debug without hitting breakpoints or printing Console.WriteLine().
✅ 2. Structured Production Logs
In production, logs are saved to disk in a structured format. You can:
Tail them from the server
Upload them to a logging platform (Seq, Datadog, ELK stack)
Automatically parse fields like timestamp, level, message, exception, etc.
This gives predictable, machine-readable logging — critical for scalable monitoring.
✅ 3. Easy Integration with Background Jobs
EasyLaunchpad uses Hangfire for background job scheduling. Serilog is integrated into:
Job execution logging
Retry and failure logs
Email queue status
Error capturing
No more “silent fails” in background processes — every action is traceable.
✅ 4. Enhanced API Logging (Optional Extension)
You can easily extend the logging to:
Log request/response for APIs
Add correlation IDs
Track user activity (e.g., login attempts, failed validations)
The modular architecture allows you to inject loggers into any service or controller via constructor injection.
🔍 Sample Log Output
Here’s a typical log entry generated by Serilog in EasyLaunchpad:
{
“Timestamp”: “2024–07–10T08:33:21.123Z”,
“Level”: “Information”,
“Message”: “User {UserId} logged in successfully.”,
“UserId”: “5dc95f1f-2cc2–4f8a-ae1b-1d29f2aa387a”
}
This is not just human-readable — it’s machine-queryable.
You can filter logs by UserId, Level, or Timestamp using modern logging dashboards or scripts.
🧱 A Developer-Friendly Logging Foundation
Unlike minimal templates, where you have to integrate logging yourself, EasyLaunchpad is:
Ready-to-use from first launch
Customizable for your own needs
Extendable with any Serilog sink (e.g., database, cloud services, Elasticsearch)
This means you spend less time configuring and more time building and scaling.
🧩 Built-In + Extendable
You can add additional log sinks in minutes:
Log.Logger = new LoggerConfiguration()
.WriteTo.Console()
.WriteTo.File(“Logs/log.txt”)
.WriteTo.Seq(“http://localhost:5341")
.CreateLogger();
Want to log in to:
Azure App Insights?
AWS CloudWatch?
A custom microservice?
Serilog makes it possible, and EasyLaunchpad makes it easy to start.
💼 Real-World Scenarios
Here are some real ways logging helps EasyLaunchpad-based apps:
Use Case and the Benefit
Login attempts — Audit user activity and failed attempts
Payment errors- Track Stripe/Paddle API errors
Email queue- Debug failed or delayed emails
Role assignment- Log admin actions for compliance
Cron jobs- Monitor background jobs in real-time
🧠 Final Thoughts
You can’t fix what you can’t see.
Whether you’re launching an MVP or running a growing SaaS platform, structured logging gives you visibility, traceability, and peace of mind.
EasyLaunchpad integrates Serilog from day one — so you’re never flying blind. You get a clean, scalable logging system with zero setup required.
No more guesswork. Just clarity.
👉 Start building with confidence. Check out EasyLaunchpad at https://easylaunchpad.com and see how production-ready logging fits into your stack.
#Serilog .NET logging#structured logs .NET Core#developer-friendly logging in boilerplate#.net development#saas starter kit#saas development company#app development#.net boilerplate
1 note
·
View note
Text
How to Build a YouTube Clone App: Tech Stack, Features & Cost Explained
Ever scrolled through YouTube and thought, “I could build this—but better”? You’re not alone. With the explosive growth of content creators and the non-stop demand for video content, building your own YouTube clone isn’t just a dream—it’s a solid business move. Whether you're targeting niche creators, regional content, or building the next big video sharing and streaming platform, there’s room in the market for innovation.
But before you dive into code or hire a dev team, let’s talk about the how. What tech stack powers a platform like YouTube? What features are must-haves? And how much does it actually cost to build something this ambitious?
In this post, we’re breaking it all down—no fluff, no filler. Just a clear roadmap to building a killer YouTube-style platform with insights from the clone app experts at Miracuves.
Core Features of a YouTube Clone App
Before picking servers or coding frameworks, you need a feature checklist. Here’s what every modern YouTube clone needs to include:
1. User Registration & Profiles
Users must be able to sign up via email or social logins. Profiles should allow for customization, channel creation, and subscriber tracking.
2. Video Upload & Encoding
Users upload video files that are auto-encoded to multiple resolutions (360p, 720p, 1080p). You’ll need a powerful media processor and cloud storage to handle this.
3. Streaming & Playback
The heart of any video platform. Adaptive bitrate streaming ensures smooth playback regardless of network speed.
4. Content Feed & Recommendations
Dynamic feeds based on trending videos, subscriptions, or AI-driven interests. The better your feed, the longer users stay.
5. Like, Comment, Share & Subscribe
Engagement drives reach. Build these features in early and make them seamless.
6. Search & Filters
Let users find content via keywords, categories, uploaders, and tags.
7. Monetization Features
Allow ads, tipping (like Super Chat), or paid content access. This is where the money lives.
8. Admin Dashboard
Moderation tools, user management, analytics, and content flagging are essential for long-term growth.
Optional Features:
Live Streaming
Playlists
Stories or Shorts
Video Premiere Countdown
Multilingual Subtitles
Media Suggestion: Feature comparison table between YouTube and your envisioned clone
Recommended Tech Stack
The tech behind YouTube is serious business, but you don’t need Google’s budget to launch a lean, high-performance YouTube clone. Here’s what we recommend at Miracuves:
Frontend (User Interface)
React.js or Vue.js – Fast rendering and reusable components
Tailwind CSS or Bootstrap – For modern, responsive UI
Next.js – Great for server-side rendering and SEO
Backend (Server-side)
Node.js with Express – Lightweight and scalable
Python/Django – Excellent for content recommendation algorithms
Laravel (PHP) – If you're going for quick setup and simplicity
Video Processing & Streaming
FFmpeg – Open-source video encoding and processing
HLS/DASH Protocols – For adaptive streaming
AWS MediaConvert or Mux – For advanced media workflows
Cloudflare Stream – Built-in CDN and encoding, fast global delivery
Storage & Database
Amazon S3 or Google Cloud Storage – For storing video content
MongoDB or PostgreSQL – For structured user and video data
Authentication & Security
JWT (JSON Web Tokens) for secure session management
OAuth 2.0 for social logins
Two-Factor Authentication (2FA) for creators and admins
Analytics & Search
Elasticsearch – Fast, scalable search
Mixpanel / Google Analytics – Track video watch time, drop-offs, engagement
AI-based recommendation engine – Python + TensorFlow or third-party API
Media Suggestion: Architecture diagram showing tech stack components and flow
Development Timeline & Team Composition
Depending on complexity, here’s a typical development breakdown:
MVP Build: 3–4 months
Full Product with Monetization: 6–8 months
Team Needed:
1–2 Frontend Developers
1 Backend Developer
1 DevOps/Cloud Engineer
1 UI/UX Designer
1 QA Tester
1 Project Manager
Want to move faster? Miracuves offers pre-built YouTube clone app solutions that can cut launch time in half.
Estimated Cost Breakdown
Here’s a rough ballpark for custom development: PhaseEstimated CostUI/UX Design$3,000 – $5,000Frontend Development$6,000 – $10,000Backend Development$8,000 – $12,000Video Processing Setup$4,000 – $6,000QA & Testing$2,000 – $4,000Cloud Infrastructure$500 – $2,000/month (post-launch)
Total Estimated Cost: $25,000 – $40,000+ depending on features and scale
Need it cheaper? Go the smart way with a customizable YouTube clone from Miracuves—less risk, faster time-to-market, and scalable from day one.
Final Thoughts
Building a YouTube clone isn’t just about copying features—it’s about creating a platform that gives creators and viewers something fresh, intuitive, and monetizable. With the right tech stack, must-have features, and a clear plan, you’re not just chasing YouTube—you’re building your own lane in the massive video sharing and streaming platform space.
At Miracuves, we help startups launch video platforms that are secure, scalable, and streaming-ready from day one. Want to build a revenue-generating video app that users love? Let’s talk.
FAQs
How much does it cost to build a YouTube clone?
Expect $25,000–$40,000 for a custom build. Ready-made solutions from Miracuves can reduce costs significantly.
Can I monetize my YouTube clone?
Absolutely. Use ads, subscriptions, tipping, pay-per-view, or affiliate integrations.
What’s the hardest part of building a video streaming app?
Video encoding, storage costs, and scaling playback across geographies. You’ll need a solid cloud setup.
Do I need to build everything from scratch?
No. Using a YouTube clone script from Miracuves saves time and still offers full customization.
How long does it take to launch?
A simple MVP may take 3–4 months. A full-feature platform can take 6–8 months. Miracuves can cut that timeline in half.
Is it legal to build a YouTube clone?
Yes, as long as you’re not copying YouTube’s trademark or copyrighted content. The tech and business model are fair game.
1 note
·
View note
Text
Implementing Elasticsearch in Django for Lightning-Fast Search
Implementing Elasticsearch in Django for Lightning-Fast Search 1. Introduction In today’s data-driven world, providing fast and accurate search functionality is crucial for user satisfaction. Django, a powerful Python web framework, offers robust tools for building web applications, but its built-in search capabilities can be limited when dealing with large datasets. This is where Elasticsearch…
0 notes
Text
ElasticSearch: The Ultimate Guide to Scalable Search & Analytics
Introduction In today’s data-driven world, businesses and developers need efficient ways to store, search, and analyze large volumes of data. This is where ElasticSearch comes in — a powerful, open-source search and analytics engine built on top of Apache Lucene. ElasticSearch is widely used for full-text search, log analytics, monitoring, and real-time data visualization.
In this blog post, we will explore ElasticSearch in-depth, covering its architecture, key features, use cases, and how to get started with it.
What is ElasticSearch?
ElasticSearch is a distributed, RESTful search and analytics engine that allows users to search, analyze, and visualize data in near real-time. It was developed by Shay Banon and released in 2010. Since then, it has become a core component of the Elastic Stack (ELK Stack), which includes Logstash for data ingestion and Kibana for visualization.
Key Features Scalability: ElasticSearch scales horizontally using a distributed architecture. Full-Text Search: Provides advanced full-text search capabilities using Apache Lucene. Real-Time Indexing: Supports real-time data indexing and searching. RESTful API: Provides a powerful and flexible API for integration with various applications. Schema-Free JSON Documents: Uses a schema-free, document-oriented approach to store data in JSON format. Aggregations: Enables advanced analytics through a powerful aggregation framework. Security: Offers role-based access control (RBAC), authentication, and encryption features. Multi-Tenancy: Supports multiple indices, making it useful for handling different datasets efficiently. ElasticSearch Architecture
Understanding ElasticSearch’s architecture is essential to leveraging its full potential. Let’s break it down:
Cluster A cluster is a collection of one or more nodes working together to store and process data. Each cluster is identified by a unique name.
Node A node is a single instance of ElasticSearch that stores data and performs indexing/search operations. There are different types of nodes:
Master Node: Manages the cluster, creates/deletes indices, and handles node management. Data Node: Stores actual data and executes search/indexing operations. Ingest Node: Prepares and processes data before indexing. Coordinating Node: Routes search queries and distributes tasks to other nodes.
Index An index is a collection of documents that share similar characteristics. It is similar to a database in a relational database management system (RDBMS).
Document A document is the basic unit of data stored in ElasticSearch. It is represented in JSON format.
Shards and Replicas Shards: An index is divided into smaller pieces called shards, which allow ElasticSearch to distribute data across multiple nodes. Replicas: Each shard can have one or more replicas to ensure high availability and fault tolerance. Use Cases of ElasticSearch
ElasticSearch is widely used in various industries. Here are some key use cases:
Full-Text Search ElasticSearch’s powerful text analysis and ranking make it ideal for implementing search functionalities in websites, e-commerce platforms, and applications.
Log and Event Analytics Companies use ElasticSearch to analyze logs generated by applications, servers, and security systems. It helps in real-time monitoring, identifying errors, and optimizing system performance.
Business Intelligence & Data Visualization ElasticSearch powers data analytics dashboards like Kibana, enabling businesses to analyze trends and make data-driven decisions.
Security Information and Event Management (SIEM) Organizations use ElasticSearch for threat detection and cybersecurity monitoring by processing security logs.
IoT and Real-Time Data Processing ElasticSearch is widely used in IoT applications for processing sensor data in real-time, making it an excellent choice for IoT developers.
Continue to the Next Step by clicking here
Best Practices for Using ElasticSearch
To get the best performance from ElasticSearch, consider the following best practices:
Proper Indexing Strategy: Use optimized index mapping and data types to improve search performance. Shard Management: Avoid excessive shards and keep a balanced shard-to-node ratio. Use Bulk API for Large Data Ingestion: Instead of inserting data one by one, use the Bulk API for batch inserts. Optimize Queries: Use filters and caching to improve query performance. Enable Security Features: Implement role-based access control (RBAC) and encryption. Monitor Performance: Use Elastic Stack monitoring tools to keep track of ElasticSearch cluster health. Challenges & Limitations
Despite its advantages, ElasticSearch has some challenges:
Memory Usage: Requires careful memory tuning and management. Complex Query Syntax: Can be difficult to master for beginners. Data Consistency: ElasticSearch follows an eventual consistency model, which may not be ideal for all applications.
0 notes
Text
How to Become a Full Stack Java Developer in 6 Months – Full Roadmap

Are you looking to kickstart your career in software development? Becoming a Full Stack Java Developer is one of the most sought-after skills in today’s tech industry. With expertise in both frontend and backend development, Full Stack Java Developers are in high demand. In this article, we will provide a six-month roadmap to help you master Full Stack Java Training in KPHB efficiently.
Why Choose Full Stack Java Development?
Java is one of the most powerful programming languages, and its robust ecosystem makes it an excellent choice for full stack development. Companies across the globe rely on Java for developing scalable, secure, and efficient applications. By mastering the Full Stack Java Training in KPHB, you can unlock numerous job opportunities and excel in your career.
6-Month Roadmap to Becoming a Full Stack Java Developer
Month 1: Core Java and Fundamentals
Before diving into advanced topics, you need to have a strong grasp of Core Java.
Topics to Cover:
Java Basics – Variables, Data Types, Operators, Control Statements
Object-Oriented Programming (OOP)
Exception Handling
Collections Framework
Multithreading & Concurrency
File Handling & Serialization
JDBC (Java Database Connectivity)
Month 2: Advanced Java and Web Development Basics
Advanced Java:
Servlets & JSP
Hibernate
Spring Core
Spring Boot Basics
Frontend Development:
HTML5, CSS3, JavaScript
Bootstrap for Responsive Design
React.js Basics
Month 3: Spring Boot & Microservices Development
Spring Boot Advanced:
Spring MVC
Spring Security
RESTful APIs Development
Microservices Architecture
Spring Cloud & Service Discovery
Database:
SQL & PL/SQL (Oracle)
CRUD Operations with Java & SQL
Month 4: DevOps and Build Tools
Version Control & Build Tools:
Git, GitHub
Maven & Gradle
DevOps Tools:
Jenkins (CI/CD Automation)
Docker & Containerization
Sonarqube (Code Quality Analysis)
Datadog for Monitoring
ELK (Elasticsearch, Logstash, Kibana) for Logging
Month 5: Testing & Deployment
Testing Frameworks:
JUnit for Unit Testing
Mockito for Mocking
JMeter for Performance Testing
Cloud Deployment:
AWS Basics
Heroku Deployment
Month 6: Agile & Final Project
Agile Tools:
Jira for Project Management
Chef for Configuration Management
Capstone Project:
Develop a Full Stack Java Application using all the learned technologies
Deploy and optimize your project
Final Thoughts
Becoming a Full Stack Java Developer requires dedication, consistent learning, and hands-on practice. By following this six-month roadmap and enrolling in a structured Full Stack Java Training in KPHB, you can fast-track your career in software development. Stay committed, build real-world projects, and keep updating yourself with the latest tools and technologies.
If you’re serious about Full Stack Java Training in KPHB, start today and take the first step towards a successful career in Java development!
#coding#programming#artificial intelligence#software engineering#javascript#javaprogramming#java#fullstack#developer
1 note
·
View note
Text
The Role of Log Frameworks in Academic Research and Data Management

In academic research, maintaining structured and well-documented data is essential for ensuring transparency, reproducibility, and efficient analysis. Just as log frameworks play a critical role in software development by tracking system behavior and debugging errors, they also serve as valuable tools for researcher’s handling large datasets, computational models, and digital experiments.
This article explores the significance of log frameworks in research, their key features, and how scholars can leverage structured logging for efficient data management and compliance.
What Is a Log Framework?
A log framework is a structured system that allows users to generate, format, store, and manage log messages. In the context of academic research, logging frameworks assist in tracking data processing workflows, computational errors, and analytical operations, ensuring that research findings remain traceable and reproducible.
Researchers working on quantitative studies, data analytics, and machine learning can benefit from logging frameworks by maintaining structured logs of their methodologies, similar to how software developers debug applications.
For further insights into structuring academic research and improving data management, scholars can explore academic writing resources that provide guidance on research documentation.
Key Features of Log Frameworks in Research
🔹 Log Level Categorization – Helps classify research data into different levels of significance (e.g., raw data logs, processing logs, and result logs). 🔹 Multiple Storage Options – Logs can be stored in databases, spreadsheets, or cloud-based repositories. 🔹 Automated Logging – Reduces manual errors by tracking computational steps in the background. 🔹 Structured Formatting – Ensures research documentation remains clear and reproducible. 🔹 Data Integrity & Compliance – Supports adherence to research integrity standards and institutional requirements.
For a more in-depth discussion on structured academic documentation, scholars can engage in free academic Q&A discussions to refine their research methodologies.
Why Are Log Frameworks Important in Academic Research?
1️⃣ Enhanced Research Reproducibility
Logging helps ensure that all data transformations, computational steps, and methodological adjustments are well-documented, allowing other researchers to replicate findings.
2️⃣ Efficient Data Monitoring & Debugging
Researchers working with complex datasets or computational tools can use log frameworks to track anomalies and discrepancies, much like software developers debug errors in applications.
3️⃣ Compliance with Ethical & Institutional Guidelines
Academic institutions and publishers require transparency in data collection and analysis. Proper logging ensures compliance with ethical standards, grant requirements, and institutional policies.
4️⃣ Long-Term Data Preservation
Structured logs help retain critical research details over time, making it easier to revisit methodologies for future studies.
To explore additional academic research tools and methodologies, scholars may access comprehensive digital libraries that provide authoritative research materials.
Popular Log Frameworks for Research & Data Analysis
Log4j (Java) 📌 Use Case: Computational modeling, simulation research 📌 Pros: Highly configurable, supports integration with data analysis platforms 📌 Cons: Requires security updates to prevent vulnerabilities
Serilog (.NET) 📌 Use Case: Quantitative research using .NET-based statistical tools 📌 Pros: Supports structured logging and integration with visualization tools 📌 Cons: Requires familiarity with .NET framework
Winston (Node.js) 📌 Use Case: Web-based academic data analysis platforms 📌 Pros: Supports real-time research data logging and cloud integration 📌 Cons: May require additional configuration for large-scale data processing
ELK Stack (Elasticsearch, Logstash, Kibana) 📌 Use Case: Large-scale academic data aggregation and visualization 📌 Pros: Allows powerful search capabilities and real-time monitoring 📌 Cons: Requires technical expertise for setup and configuration
How to Choose the Right Log Framework for Academic Research
When selecting a log framework for research purposes, consider:
✅ Compatibility with Research Tools – Ensure it integrates with statistical or data management software. ✅ Scalability – Can it handle large datasets over time? ✅ User Accessibility – Does it require advanced programming knowledge? ✅ Data Security & Ethics Compliance – Does it meet institutional and publication standards?
Conclusion
Log frameworks are invaluable for researchers handling data-intensive studies, ensuring transparency, reproducibility, and compliance. Whether used for debugging computational errors, tracking methodological changes, or preserving data integrity, structured logging is a critical component of academic research.
For further guidance on structuring research documents, scholars can explore academic writing resources and engage in peer discussions to enhance their methodologies. Additionally, accessing digital academic libraries can provide further insights into data-driven research.
By incorporating effective log frameworks, researchers can elevate the quality and reliability of their academic contributions, ensuring their work remains impactful and reproducible.
0 notes
Text
How to Monitor and Debug Python-Based ETL Pipelines
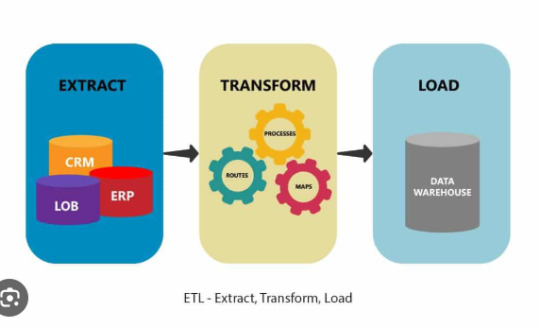
In the world of data engineering, Extract, Transform, Load (ETL) Python workflows are the backbone of moving, cleaning, and transforming data into actionable insights. However, even the most well-designed ETL pipelines can run into issues like slow performance, data mismatches, or outright failures. To ensure smooth operation, monitoring and debugging Python-based ETL pipelines is critical. This article will guide you through practical strategies and tools to monitor and debug ETL workflows effectively.
Why Monitor Python-Based ETL Pipelines?
Monitoring is essential to maintain the reliability of ETL pipelines. It helps identify bottlenecks, spot anomalies, and ensure data integrity. Without robust monitoring, errors may go unnoticed until they cause significant downstream issues, such as corrupted reports or unresponsive applications.
Common Challenges in Python ETL Pipelines
Before diving into solutions, let’s explore common issues faced when running ETL pipelines:
Data Extraction Failures: API timeouts, file unavailability, or incorrect data formats can disrupt the extraction process.
Transformation Errors: Logical flaws in data transformation scripts can lead to inaccurate results.
Load Failures: Issues like database connectivity problems or schema mismatches can hinder the loading process.
Performance Bottlenecks: Handling large datasets may slow down pipelines if not optimized.
Missing Data Validation: Without proper checks, pipelines may process incomplete or corrupt data.
Effective Monitoring Strategies for ETL Pipelines
1. Use Logging for Transparency
Logging is the cornerstone of monitoring ETL pipelines. Python’s logging library allows you to capture details about pipeline execution, including errors, processing times, and data anomalies. Implement structured logging to make logs machine-readable, which simplifies debugging.
2. Monitor Pipeline Metrics
Track metrics like execution time, row counts, and resource utilization to spot inefficiencies. Tools like Prometheus and Grafana can visualize these metrics, providing actionable insights.
3. Set Up Alerts for Failures
Use tools like Apache Airflow, Dagster, or custom scripts to trigger alerts when a pipeline fails. Alerts can be sent via email, Slack, or SMS to ensure prompt action.
Debugging Techniques for Python-Based ETL Pipelines
1. Identify the Faulty Stage
Divide your pipeline into stages (Extract, Transform, Load) and isolate the problematic one. For instance:
If the error occurs during extraction, check the data source connectivity.
If transformation fails, debug the logic in your Python code.
For loading errors, examine database logs for schema mismatches or connectivity issues.
2. Utilize Python Debugging Tools
Python’s built-in debugger, pdb, is invaluable for inspecting code at runtime. You can set breakpoints to pause execution and examine variable values.
3. Test with Mock Data
Create unit tests using frameworks like pytest to simulate different pipeline scenarios. Mock external dependencies (e.g., databases, APIs) to test your logic in isolation.
4. Validate Data at Every Step
Incorporate data validation checks to ensure input, intermediate, and output data meet expectations. Libraries like pandas and great_expectations simplify this process.
Tools for Monitoring and Debugging ETL Pipelines
Apache Airflow: Schedule, monitor, and manage workflows with built-in task-level logging and alerting.
Dagster: Provides observability with real-time logs and metadata tracking.
DataDog: Monitors application performance and sends alerts for anomalies.
ELK Stack: Use Elasticsearch, Logstash, and Kibana to collect and analyze logs.
Best Practices for Reliable ETL Pipelines
Implement Retry Mechanisms: Use libraries like tenacity to retry failed tasks automatically.
Version Control Your Code: Use Git to track changes and quickly revert to a stable version if needed.
Optimize Resource Usage: Profile your code with tools like cProfile and use parallel processing libraries (e.g., Dask, multiprocessing) for efficiency.
Document Your Pipeline: Clear documentation helps identify potential issues faster.
Conclusion
Monitoring and debugging Python-based ETL pipelines require a mix of proactive tracking and reactive problem-solving. Leveraging tools like logging frameworks, Airflow, and testing libraries, you can ensure your Extract, Transform, Load Python workflows are robust and reliable. By implementing the strategies discussed in this article, you’ll minimize downtime, improve performance, and maintain data integrity throughout your pipelines.
0 notes
Text
AIOps Platform Development: Leveraging Big Data for Smarter Operations
In the ever-evolving world of IT operations, businesses face increasing complexity and the need for greater efficiency. As organizations scale and digital infrastructures grow, it becomes more difficult to manage data, predict system failures, and maintain a seamless user experience. This is where AIOps—Artificial Intelligence for IT Operations—comes into play. By leveraging Big Data, AIOps platforms are revolutionizing how businesses approach IT management, automating operations, enhancing predictive analytics, and optimizing decision-making processes.

In this blog, we will explore the significance of AIOps platform development in modern IT environments, how it harnesses the power of Big Data, and why its adoption is crucial for organizations looking to stay ahead of the curve.
What is AIOps?
AIOps is the application of Artificial Intelligence (AI) and Machine Learning (ML) technologies to automate and enhance IT operations. It combines big data analytics, event correlation, anomaly detection, and machine learning to provide actionable insights that can improve the efficiency, reliability, and scalability of IT systems.
AIOps platforms are designed to help IT teams manage complex, large-scale environments by analyzing vast amounts of operational data in real time. They help organizations detect and resolve issues before they escalate, predict system failures, optimize resource utilization, and enhance overall system performance. In short, AIOps enables organizations to operate smarter, faster, and more effectively.
The Role of Big Data in AIOps
The backbone of AIOps is Big Data. IT operations generate vast amounts of data, from logs, metrics, and events to network traffic, performance data, and user interactions. Traditional monitoring tools struggle to process and analyze this volume of data in a timely and meaningful way. However, Big Data technologies provide the necessary infrastructure and tools to handle, store, and process such massive datasets.
Here’s how Big Data plays a crucial role in AIOps development:
1. Data Integration from Diverse Sources
IT environments are often heterogeneous, with data coming from various sources: servers, cloud platforms, applications, databases, network devices, and security systems. A robust AIOps platform integrates these data streams into a centralized system, allowing IT teams to monitor performance, track incidents, and gain insights from a unified view of the ecosystem.
Big Data technologies like Apache Kafka and Apache Flink provide the framework to collect and stream data from these diverse sources. This integrated data allows for more accurate event correlation and faster identification of problems, even when the cause may be complex or involve multiple systems.
2. Real-time Processing and Analytics
The ability to analyze data in real time is one of the cornerstones of AIOps. Big Data tools enable the rapid ingestion, processing, and analysis of vast amounts of operational data as it is generated. Technologies such as Apache Spark, Hadoop, and Elasticsearch are commonly used to perform real-time analytics, enabling AIOps platforms to detect anomalies, monitor system performance, and provide actionable insights instantly.
For instance, when an IT system encounters an unusual spike in traffic or resource usage, the AIOps platform can detect this anomaly in real time, triggering an automatic alert or even taking corrective actions based on predefined rules or AI models. This level of proactive monitoring is crucial for minimizing downtime and ensuring that businesses can continue to operate smoothly.
3. Predictive Analytics for Proactive Issue Resolution
One of the most powerful applications of Big Data in AIOps is its ability to predict and prevent IT issues before they occur. By analyzing historical data, AIOps platforms can identify patterns and trends that may indicate impending failures or performance degradation.
For example, if an application is consistently experiencing slowdowns during peak usage times, the AIOps platform can predict when the system is likely to fail, enabling IT teams to take preventive measures in advance. By integrating machine learning models with historical data, AIOps can continuously improve its predictions, enhancing the accuracy of failure forecasts.
4. Enhanced Anomaly Detection
With the sheer volume and variety of data generated in modern IT environments, traditional anomaly detection techniques often fail to keep up. Big Data technologies provide the foundation for advanced anomaly detection techniques, including machine learning models that can identify even the most subtle deviations from normal behavior.
For example, an AIOps platform powered by Big Data might use machine learning algorithms like K-means clustering or Isolation Forest to analyze vast amounts of metrics and detect anomalies in performance, security events, or infrastructure usage. The system can then alert the operations team about potential issues, empowering them to take action before these anomalies escalate into full-blown problems.
5. Root Cause Analysis and Event Correlation
In complex IT environments, problems rarely occur in isolation. One issue might trigger a cascade of failures across multiple systems, making it difficult to identify the root cause. Big Data tools help AIOps platforms correlate events across various systems, enabling a more accurate and timely diagnosis of underlying issues.
For example, if an application crashes after a network outage, Big Data tools can correlate network logs, application logs, and server metrics to pinpoint the exact sequence of events that led to the crash. This enables IT teams to resolve issues more efficiently, reducing downtime and the impact on end users.
Key Benefits of AIOps Powered by Big Data
The integration of Big Data into AIOps platforms brings several key benefits that can significantly improve the way IT operations are managed:
1. Faster Issue Detection and Resolution
With real-time data processing and predictive analytics, AIOps platforms can identify and resolve issues much faster than traditional methods. Automated responses can even be triggered in some cases, allowing for immediate remediation without human intervention.
2. Improved Operational Efficiency
AIOps platforms automate manual tasks, such as log analysis, event correlation, and root cause diagnosis, allowing IT teams to focus on more strategic activities. This leads to significant operational efficiency gains and reduced workload for IT staff.
3. Cost Savings
By automating IT operations, reducing downtime, and predicting failures, AIOps helps businesses avoid costly outages and operational inefficiencies. Additionally, AIOps can optimize resource utilization, ensuring that IT resources are allocated effectively, which can further reduce costs.
4. Better Scalability
AIOps platforms are designed to handle large volumes of data, making them scalable as organizations grow. With Big Data infrastructure in place, companies can scale their IT operations seamlessly without worrying about the limitations of traditional monitoring tools.
5. Enhanced Security
By continuously monitoring data and analyzing patterns, AIOps platforms can detect potential security threats, such as unusual network traffic or unauthorized access attempts. Big Data-driven insights can help IT teams take proactive measures to protect against cyberattacks and mitigate risks.
Challenges in AIOps Development
While the potential of AIOps is clear, its implementation is not without challenges:
Data Quality and Integration: Integrating data from disparate sources and ensuring that the data is clean and consistent can be a significant challenge.
Complexity of Machine Learning Models: Developing machine learning models that can accurately predict failures and detect anomalies requires expertise and careful tuning.
Real-time Processing Demands: Handling large volumes of data in real time demands a robust and scalable infrastructure.
Change Management: As organizations adopt AIOps, it may require a shift in how IT teams work and the tools they use, which can face resistance.
Conclusion
The future of IT operations lies in the intersection of Artificial Intelligence and Big Data. AIOps platforms, powered by Big Data technologies, are transforming how businesses manage their IT systems by enabling smarter, more efficient operations. By leveraging predictive analytics, real-time data processing, and anomaly detection, AIOps platform development can help businesses reduce downtime, improve system performance, and enhance overall operational efficiency. However, implementing AIOps requires overcoming challenges related to data integration, model accuracy, and real-time demands. As organizations continue to adopt these technologies, the role of AIOps in optimizing IT operations will only grow, driving businesses toward greater agility and innovation.
In an era of data-driven decision-making, those who embrace AIOps will be better equipped to navigate the complexities of modern IT environments, ensuring smoother operations and a competitive edge in the marketplace.
0 notes
Text
IT Jobs for jobseekerspage.com
It seems like you’re considering the concept of "IT Jobs for JobseekersPage.com", possibly as a dedicated platform for connecting IT professionals with employers. Here's how you can structure and position JobseekersPage.com for maximum impact:
Concept: IT Jobs at JobseekersPage.com
Objective
To provide a user-friendly platform where IT professionals can discover job opportunities, showcase their skills, and connect with employers in the tech industry.
Tagline Ideas
"Empowering IT Careers, One Job at a Time."
"Your IT Career Starts Here!"
"Tech Opportunities, Tailored for You."
Core Features for IT Job Seekers
Tailored IT Job Search
Skill-Based Matching: Connect job seekers with roles requiring specific skills like Python, Java, Cloud Computing, etc.
Tech-Specific Job Categories:
Software Development
Data Science & AI
Cybersecurity
IT Support & Infrastructure
DevOps & Cloud Engineering
Location Flexibility: Include options for remote, hybrid, or on-site jobs.
Professional Profiles
Highlight Skills: Display certifications (AWS, Azure, CISSP, etc.), tech stacks, and project experience.
Portfolio Integration: Link to GitHub, Bitbucket, or personal websites.
Resume Optimization: Help users create ATS-friendly resumes directly on the site.
Job Alerts
Notify users of new listings matching their profile.
Provide weekly summaries of trending IT jobs.
Skill Validation
Offer coding assessments and technical quizzes.
Award badges or certifications to enhance profiles.
Features for Employers
Post IT Job Openings
Simple forms to post jobs with advanced tagging for better visibility.
Include detailed requirements for skills, experience, and tools (e.g., frameworks, languages).
Search IT Talent
Browse profiles based on skill sets, certifications, and experience.
Advanced filters like availability, desired salary, and location.
Company Branding
Showcase company culture, benefits, and team highlights.
Add videos or photos of offices to attract talent.
Additional Tools for Engagement
Resource Hub
Career Guides: How to ace technical interviews, create standout resumes, and network effectively.
Industry Trends: Articles on emerging technologies and high-demand skills.
Training Partnerships: Link to Coursera, Udemy, or internal courses for IT upskilling.
Community Forum
Discussion boards for tech topics, job hunting tips, and general Q&A.
Support for sharing interview experiences and employer reviews.
Platform Monetization
Premium Listings: Employers pay to highlight job postings.
Sponsored Content: Feature training programs or partner companies.
Freemium Model: Basic access for free, with paid features like resume boosting or unlimited applications.
Technical Implementation
Frontend: React.js or Vue.js for a sleek user interface.
Backend: Django or Node.js for managing job listings, profiles, and data securely.
Database: PostgreSQL for reliable data management.
Search Optimization: Elasticsearch for fast job search responses.
Would you like help with building a demo interface, creating specific content, or developing the platform's branding? Let me know!
0 notes
Text
Python Developer
Skills: Strong programming skills in Python and experience with frameworks like FastAPI. Good programming skills in frontend development using React. Experience deploying and managing containerized applications (Docker/Podman). Solid knowledge of AWS services, including compute (Lambda, ECS, Fargate), storage (S3, DynamoDB), and messaging (SQS, SNS). Experience working with Elasticsearch and…
0 notes
Text
Mastering Elasticsearch Data Management with River Plug-ins
Introduction Handling high volume data with Elasticsearch River plug-ins is a crucial aspect of data processing and analytics in the era of Big Data. Elasticsearch, a popular search and analytics engine, provides a robust framework for ingesting and processing large volumes of data. River plug-ins, a feature introduced in Elasticsearch 0.90, allow users to effortlessly integrate various data…
0 notes
Text
Custom AI Development Services - Grow Your Business Potential

AI Development Company
As a reputable Artificial Intelligence Development Company, Bizvertex provides creative AI Development Solutions for organizations using our experience in AI app development. Our expert AI developers provide customized solutions to meet the specific needs of various sectors, such as intelligent chatbots, predictive analytics, and machine learning algorithms. Our custom AI development services are intended to empower your organization and produce meaningful results as it embarks on its digital transformation path.
AI Development Services That We Offer
Our AI development services are known to unlock the potential of vast amounts of data for driving tangible business results. Being a well-established AI solution provider, we specialize in leveraging the power of AI to transform raw data into actionable insights, paving the way for operational efficiency and enhanced decision-making. Here are our reliably intelligent AI Services that we convert your vision into reality.
Generative AI
Smart AI Assistants and Chatbot
AI/ML Strategy Consulting
AI Chatbot Development
PoC and MVP Development
Recommendation Engines
AI Security
AI Design
AIOps
AI-as-a-Service
Automation Solutions
Predictive Modeling
Data Science Consulting
Unlock Strategic Growth for Your Business With Our AI Know-how
Machine Learning
We use machine learning methods to enable sophisticated data analysis and prediction capabilities. This enables us to create solutions such as recommendation engines and predictive maintenance tools.
Deep Learning
We use deep learning techniques to develop effective solutions for complex data analysis tasks like sentiment analysis and language translation.
Predictive Analytics
We use statistical algorithms and machine learning approaches to create solutions that predict future trends and behaviours, allowing organisations to make informed strategic decisions.
Natural Language Processing
Our NLP knowledge enables us to create sentiment analysis, language translation, and other systems that efficiently process and analyse human language data.
Data Science
Bizvertex's data science skills include data cleansing, analysis, and interpretation, resulting in significant insights that drive informed decision-making and corporate strategy.
Computer Vision
Our computer vision expertise enables the extraction, analysis, and comprehension of visual information from photos or videos, which powers a wide range of applications across industries.
Industries Where Our AI Development Services Excel
Healthcare
Banking and Finance
Restaurant
eCommerce
Supply Chain and Logistics
Insurance
Social Networking
Games and Sports
Travel
Aviation
Real Estate
Education
On-Demand
Entertainment
Government
Agriculture
Manufacturing
Automotive
AI Models We Have Expertise In
GPT-4o
Llama-3
PaLM-2
Claude
DALL.E 2
Whisper
Stable Diffusion
Phi-2
Google Gemini
Vicuna
Mistral
Bloom-560m
Custom Artificial Intelligence Solutions That We Offer
We specialise in designing innovative artificial intelligence (AI) solutions that are tailored to your specific business objectives. We provide the following solutions.
Personlization
Enhanced Security
Optimized Operations
Decision Support Systems
Product Development
Tech Stack That We Using For AI Development
Languages
Scala
Java
Golang
Python
C++
Mobility
Android
iOS
Cross Platform
Python
Windows
Frameworks
Node JS
Angular JS
Vue.JS
React JS
Cloud
AWS
Microsoft Azure
Google Cloud
Thing Worx
C++
SDK
Kotlin
Ionic
Xamarin
React Native
Hardware
Raspberry
Arduino
BeagleBone
OCR
Tesseract
TensorFlow
Copyfish
ABBYY Finereader
OCR.Space
Go
Data
Apache Hadoop
Apache Kafka
OpenTSDB
Elasticsearch
NLP
Wit.ai
Dialogflow
Amazon Lex
Luis
Watson Assistant
Why Choose Bizvertex for AI Development?
Bizvertex the leading AI Development Company that provides unique AI solutions to help businesses increase their performance and efficiency by automating business processes. We provide future-proof AI solutions and fine-tuned AI models that are tailored to your specific business objectives, allowing you to accelerate AI adoption while lowering ongoing tuning expenses.
As a leading AI solutions provider, our major objective is to fulfill our customers' business visions through cutting-edge AI services tailored to a variety of business specializations. Hire AI developers from Bizvertex, which provides turnkey AI solutions and better ideas for your business challenges.
#AI Development#AI Development Services#Custom AI Development Services#AI Development Company#AI Development Service Provider#AI Development Solutions
0 notes